Last week the UK Agriculture and Horticulture Development Board (AHDB) announced an industry consultation to develop a set of principles (code) to promote the sharing of farm data. Happily, we at Rezare UK have been awarded the contract to run this project based on our unique agridata expertise and our significant experience in developing a code in NZ.
Improving the flow of data from farms to other organisations is seen (rightly) by the AHDB as part of the productivity agenda for UK agriculture, but there remain significant barriers to getting the data flowing in practice mainly because of issues around trust and interoperability of disparate sets of data.
While the code will go someway towards addressing issues of trust (and start to build some alignment across industry on best practice when it comes to sharing and using farm data), other issues will also need to be addressed going forward beyond the code itself, particularly the more technical aspects of exchanging and using the data.
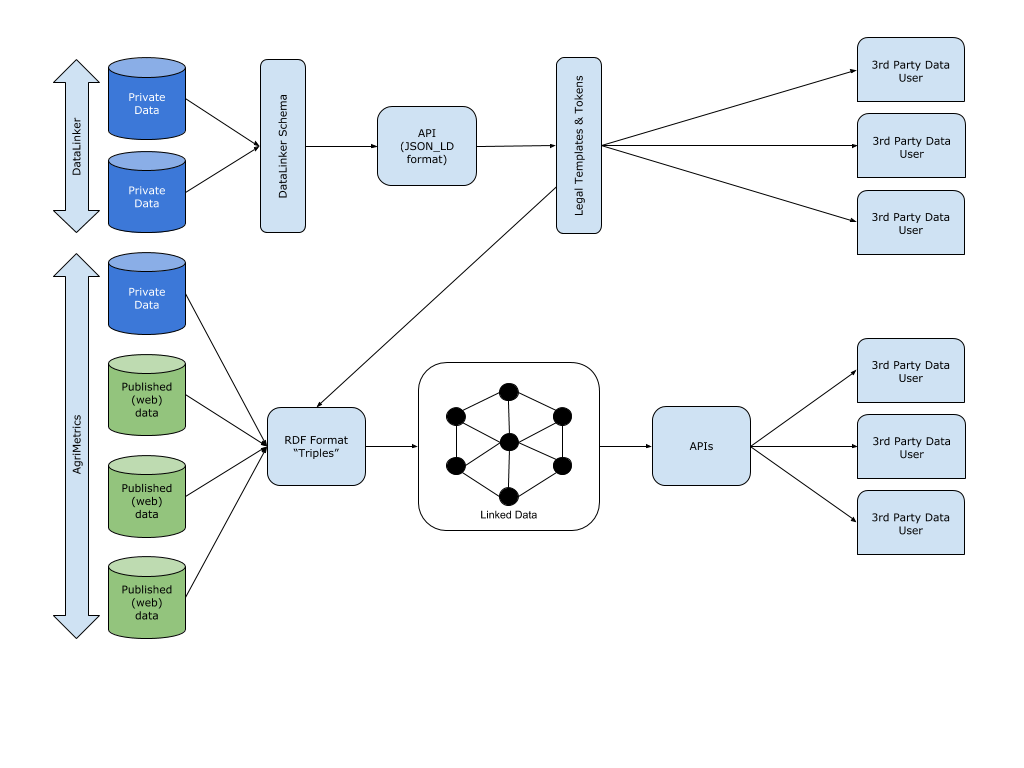
Two really good examples of dealing with this have emerged in the past couple of years – DataLinker in NZ and Agrimetrics in the UK. These two approaches (the latter is one of four UK government agritech centres of excellence) while quite different in nature (and to a degree in objectives), are actually also potentially very complimentary.
DataLinker works on a model where no one party becomes the single repository and broker of farm data. Instead, data owners build APIs to standardised schema and do this once only so that permissioned third parties can access that data in a known way. The exchange of data between the owner and user of it (“consumer”) is a bilateral relationship where DataLinker provides the permissioning (tokens) and legal frameworks (templated agreements) to streamline and standardise the process.
DataLinker assumes that each potential system is in fact its own “locker” (store of data) with one or more types of data. Users of some sort already interact with those systems, so what DataLinker does is standardise the way of finding which systems have which types of data (the findable F in FAIR data sharing) and in which formats (the interoperable I in FAIR). It specifies the method by which organisations agree data access rules and users provide permission (together, the accessible A of FAIR), with the result that the data is reusable (the R in FAIR). DataLinker has been focused more on the farmer or user-facing sharing of data than for broad data access necessary for researchers for example (at least without organisations explicitly addressing this).
Agrimetrics in the UK employs the semantic web whereby publicly available data (published on the web) or private data made available under a licence agreement is organised according to a Resource Description Framework (RDF). Each data entity is described as a “triple” (subject-predicate-object) and in that way stored data becomes machine readable by being linked to other data entities. The data contributed is effectively “held” by Agrimetrics and then exposed through APIs (charged or free) under licence for third parties to use.
Agrimetrics is focused on big data and using semantic web is tagging or structuring large datasets in public HTML documents (and other data) in a way that makes it machine recognisable and readable.
In essence the two approaches can be differentiated thus:
- DataLinker is a network approach – a set of protocols and standards that allow myriad parties to exchange and share data in multiple bilateral (albeit mostly templated) arrangements through standardised APIs.
- Agrimetrics is a hub approach – where data is is shared to the Agrimetrics “centre” where it is stored, manipulated and interpreted before being shared as a more user-friendly asset under licence through APIs.
In many ways Agrimetrics is the more comprehensive since it seeks not only to broker data exchange but also to add value to the data by linking it and manipulating it to meet a particular consumer’s need. It can handle structured or unstructured data. This is potentially very powerful as it allows a consumer of the data to draw on Agrimetrics’ technical know-how and capacity to do increasingly clever and machine-learning based activities with the data. In other words, Agrimetrics can offer a one-stop-shop for brokering and adding value to data.
However, there are also problems with the approach. It assumes a high degree of integrity and legal rigour being exercised by Agrimetrics since the data sharers are effectively “letting go” of their data to be stored and used by an organisation that is looking to commercialise it. And in the absence of private data holders being prepared to release data, Agrimetrics is only as good as the publicly available (web published) data.
DataLinker does not (and is not intended to) become involved in negotiating commercial deals to share data. Nor does it become involved in managing, manipulating or interpreting the data. It is largely a hand-off approach designed to facilitate the network, not control it. But the adoption of the standardised schemas means there is an IT burden on the data sharers – either in-house or outsourced – to build compliant APIs.
So is one approach likely to prevail? Most likely not and it’s actually preferable for the two to co-exist and complement each other. Here’s why:
- First, because culturally the DataLinker approach is more aligned to putting the interests of the farmer first and right now farmer trust in how their data is controlled and used is becoming almost the biggest blocker to progress
- Second, because it is unlikely industry will want to have all its eggs in the one basket
- Third, because the horsepower in Agrimetrics is potentially a game changer in terms of releasing real innovation based on farm data and thus demonstrating the value proposition to farmers from sharing their data (another piece of the sharing jigsaw that is missing)
- Fourth, because the DataLinker approach through its JSON_LD APIs means data can be “readied” for consumption in a semantic way which would complement the success of Agrimetrics
- And fifth, because the semantic web is likely to be a long-term approach favoured particularly by the research community within the agrifood sector.
There are other concepts for farm data sharing that are being considered around the globe.
For example, Wageningen University in the Netherlands has proposed a Farm Data Train which effectively creates a number of data lockers (stores), all with the same API and approach to authorisation, which means their interfaces in effect align closely to what is proposed in DataLinker. At present this concept is focused more on plant breeding data but it could easily grow outwards.
So what’s my point? Well, as can be seen, there is more than one way to skin the proverbial cat. What’s important is for the sector to provide space for the approaches to breathe so that there is increased opportunity for innovation to deliver against the productivity agenda. That’ll need some collaboration and collaborative thinking and in the UK we shall, in the coming months, discover how its agri sector wants to address these issues.
It’s a great time to be involved in agridata and better still that Rezare are in the thick of shaping the future.